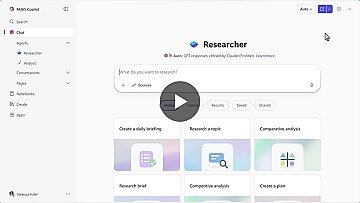
Introducing Critique, a new multi-model deep research system in M365 Copilot. You can use multiple models together to generate optimal responses and reports. Available today in Frontier: https://lnkd.in/g3mzcpk6
This is a fascinating leap in multi-model intelligence, especially the way Critique separates generation from evaluation. It's reminiscent of peer-review processes, which ensures that AI-generated content is held to a high standard of accuracy and depth. By integrating a structured review phase, it seems like you're pushing the boundaries of what AI can achieve in generating reliable and comprehensive research outputs. In our work, we've seen the importance of validating claims and grounding them in solid evidence, so it's intriguing to watch how this architecture might handle such tasks. The improvements in depth of analysis and presentation quality are impressive and suggest a more refined interaction with complex research data. I'm curious how such advancements might influence other domains, especially where precision and detail are crucial. Well done to the team!
Interesting direction, but multi-model setups aren’t exactly new anymore. The real question is whether this actually improves outcomes in day-to-day workflows, not just how many models are involved behind the scenes. If it can move from “better responses” to actually doing real work across tools, that’s when it becomes a real shift.
This is a significant step toward how enterprise AI should actually work. With Microsoft 365 Copilot moving into multi-model orchestration, we’re seeing a shift from: → Single model outputs → To composed intelligence systems Why this matters in Artificial Intelligence: → Different models have different strengths (reasoning, retrieval, speed, cost) → Combining them = higher accuracy + better decision support → Enables research-grade outputs, not just summaries This is essentially bringing: → Ensemble thinking into everyday workflows → AI collaboration behind the scenes → More reliable, context-aware reporting The real unlock: AI stops being a single assistant… and becomes a coordinated system of specialists. That’s how you move from “interesting outputs” → trusted business insights.
From Win98 to a bloated OS full of ads that artificially obsoletes perfectly good hardware—switching to Linux was the best move I ever made. I pay for an MS Business plan but have completely abandoned Copilot. Announcing 'Critique' as revolutionary is wild when you can just build a fair technological stack. Tools like Perplexity Deep Research, Cursor and Anthropic , already do multi-model orchestration much better, without the MS lock-in. Ultimately, the push for these enterprise features highlights the extreme overvaluation of OpenAI . We are seeing a severe under-delivery of real, practical utility for the average person. Over-promising and under-delivering isn't innovation—it's just driving the current wave of tech unemployment and job insecurity." #Theyhavenoideawhattheyaredoinginflation #Linux #TechIndustry #AIHype #microflation #SoftwareEngineering #FutureOfWork
Yes, this is a primary use case - augmenting and extending an inherent human attribute ... instead of trying to create new ones. Bravo Microsoft
This is a big signal of where AI is heading next. We’re moving beyond single-model outputs… into systems that can critique, refine, and improve themselves. That shift from generation → evaluation is huge. Because the real bottleneck in AI today isn’t just creating outputs — it’s ensuring quality, accuracy, and reliability at scale. Multi-model critique systems feel like the early foundation of truly agentic AI. How I see this as a builder: This isn’t just a feature — it’s a pattern. Multiple models working together: One generates One critiques One refines That’s how you move closer to production-grade intelligence. I’ve been thinking a lot about this — the future products won’t rely on a single LLM, they’ll be built as AI systems with feedback loops. That’s where real differentiation will happen. Exciting direction from Microsoft — this is going to shape how we build AI apps going forward 🚀 #ArtificialIntelligence #AI #GenerativeAI #AIAgents #MachineLearning #Innovation #Technology #SaaS #FutureOfWork
Introducing Critique: a new multi-model deep research system within M365 Copilot that allows multiple models to be used in parallel to collaboratively produce superior answers and reports. Available today at Frontier, it significantly improves research and decision-making efficiency.
I’ve tested this multi-model approach on research for complex major multi-million dollar deals , using one model to critique another’s output and the results were genuinely impressive. But it raises a critical governance question: who audits the auditors? A reviewer model can catch factual errors, but its own biases, training blind spots, and alignment drift remain unchecked without a transparent oversight layer. The risk is that we optimize for internal consistency and benchmark performance while missing deeper issues — source provenance, conflicting value judgments across labs, or subtle reinforcement of hidden assumptions. The real accountability gap isn’t just about which model leads. It’s about: ∙ Who defines the rubric for the reviewer? ∙ How do users especially on high value stakes research such as million-dollar complex decisions get visibility into those meta-level choices? Capability is scaling fast. Hoping governance keeps pace so trust can scale with it.
Impressive move. Multi-model collaboration is where real productivity gains will happen, not just single AI outputs. In travel tech, we’re already seeing similar patterns. Combining flight API, hotel API, and dynamic pricing engines gives far better conversion than isolated systems. The real edge is not AI itself, but how well businesses integrate multiple intelligence layers into one workflow. Curious, how do you see this evolving for domain-specific industries like travel and OTA platforms?
To view or add a comment, sign in