Summary
AI decision engines act as a real-time brain that turns predictions into the best next action for each customer. They combine ML with business rules to optimize timing, channel, and offers while respecting constraints. Unlike traditional tools, they can suppress low-value actions, focus on uplift (not just propensity), and prove impact through incremental lift. Key use cases include cart recovery, personalization, send-time optimization, and churn prevention.
Campaign teams configure many segment-specific rules, then customer behavior shifts and those rules break. An artificial intelligence (AI) decision engine automates that logic by evaluating customer data, scoring possible actions against business rules and machine learning (ML) predictions, and returning the optimal next step for each individual in real time.
This article explains what decision engines are, how they differ from rules engines and recommendation systems, and when hybrid approaches work best. You’ll learn how to implement decisioning for next-best action, send-time optimization, and cart recovery, and how to measure incremental lift through holdout testing.
We’ll also cover the data requirements most teams miss, the guardrails that enable trust, and how Insider One’s unified platform powers AI decisioning across channels without added complexity.
What should you know at a glance?
An AI decision engine is a system that evaluates customer data, scores possible actions against business rules and ML predictions, and returns the optimal next step for each individual in real time.
- Decision engines sit between your customer data platform (CDP) and channel execution layer, selecting the best action from many candidates while enforcing constraints like frequency caps and consent rules
- The best decision is sometimes no decision: suppressing low-value actions prevents fatigue and protects margins
- Measuring incremental lift through holdout testing proves actual value, not just attributed conversions
What is an AI decision engine?
Campaign teams spend hours configuring if/then rules across many segments, but customer behavior shifts and those rules break. A decision engine automates that logic.
An AI decision engine ingests customer data, evaluates candidate actions against business rules and ML predictions, and returns the optimal next step for each individual in real time. This means you define objectives and constraints once, and the engine handles selection across channels.
Decision engines get confused with related concepts. Here’s how they differ:
| Term | What it does | Key difference from decision engine |
| Rules engine | Executes deterministic if/then logic | No learning; requires manual rule updates |
| Recommendation engine | Ranks products or content | Narrower scope; typically lacks policy constraints |
| Decision intelligence platform | Strategic simulation and scenario planning | Broader scope; often offline or batch-oriented |
| Analytics dashboard | Reports on past performance | Descriptive, not prescriptive |
In your marketing stack, decision engines sit between the data layer and the execution layer. They consume features from the customer data platform, apply policy, and return actions. The orchestration layer then triggers the selected channel action.
This article focuses on decision engines for marketing and customer experience use cases, not fraud detection or credit underwriting, though the architecture overlaps.
When should you use a decision engine vs. a rules engine?
Your compliance team wants deterministic, auditable logic. Your growth team wants adaptive optimization. Many teams need a way to balance explainability and performance.
A few patterns help resolve the tension:
- Pure rules: Best when regulatory requirements demand full explainability and audit trails. Manual maintenance as conditions change, and no learning from outcomes
- Hybrid rules + ML: Rules gate eligibility and constraints; ML scores within the eligible set. You get explainability at the policy layer with optimization within guardrails. Requires clear ownership boundaries between policy and model teams
- Adaptive (ML-first): The model selects the action; rules serve only as hard stops. Best when speed-to-learn matters more than per-decision explainability. Harder to audit and requires robust monitoring for drift
Consider a retail brand running a cart abandonment flow. The rules engine checks: Is the cart value above threshold? Has the customer received a message recently? Is consent valid? If all pass, the decision engine scores multiple message variants and selects the one with highest expected value.
If your industry has regulatory explainability requirements (financial services, healthcare), start with hybrid. If you’re optimizing high-volume, low-stakes decisions like content slot ranking, adaptive works well.If your team lacks ML expertise and your use cases are stable, pure rules often suffice.
Platforms with pre-built predictive models; churn likelihood, purchase propensity, product affinity; reduce the ML expertise barrier significantly, making hybrid approaches accessible without dedicated data science teams.
Many teams start with more complexity than their data supports, especially before they have outcome logs for model training. If you don’t have outcome data to train models, start with rules and instrument logging. You can layer in ML once you have feedback.
How AI decision engines work in customer engagement
A customer adds an item to cart, browses a few more products, then goes idle. In near real time, the decision engine must determine whether to show an exit-intent overlay, send a push notification, do nothing, or queue an email for later.
What data foundation does decisioning need?
Most implementations fail because specific data requirements aren’t met.
- Identity resolution rate: If most events don’t tie to a known profile, your engine makes blind guesses. Check your cross-device and cross-session match rates before investing in decisioning
- Data freshness: Stale data produce stale decisions. For real-time use cases like exit intent, data must refresh quickly. For batch use cases like daily email sends, hourly freshness is often sufficient
- Outcome logging: Decision engines learn from feedback. If you can’t tie actions back to outcomes (purchase, churn, support ticket), you can’t measure lift or retrain models
Teams that skip data readiness end up with a decision engine that behaves like a more complex rules engine.
How do hybrid decisioning patterns work?
Where does the model end and the policy begin? Most implementations fail because this boundary is unclear.
A standard hybrid pattern follows this logic:
- Check hard constraints (consent, exclusion window, inventory)
- If any fail, return “do nothing”
- Generate candidate actions (offers, messages, channels)
- Score each candidate: expected_value = P(conversion) × value × uplift_adjustment
- Apply soft constraints (frequency cap, budget, fairness)
- Select top action; log decision with reason codes
Propensity alone tells you who’s likely to convert. Uplift tells you who’s likely to convert because of your action. Without uplift modeling, you waste budget on customers who would have converted anyway.
Every decision should log why it was made. This enables debugging, audit, and model improvement. If you can’t explain why a customer received a particular offer, you can’t trust the system.
And sometimes the best decision is no decision. If the expected value is below threshold, suppress the action.
How do orchestration and feedback loops work?
You’ve built the engine, deployed it, and actions are firing. But you’re not logging decisions in a way that lets you measure whether they worked.
A minimum viable decision log includes:
- Decision ID: Unique identifier
- Profile ID: Customer identifier
- Timestamp: When the decision was made
- Candidate actions: What was considered
- Selected action: What was chosen
- Reason codes: Why this action won
- Outcome: What happened (conversion, no response, unsubscribe)
Without this schema, you can’t run counterfactual analysis, detect drift, or prove incrementality.
Monitor system metrics in real time, decision metrics daily, model metrics weekly, and business metrics monthly.
Which AI decision engine use cases matter most for marketing and CX?
Not every decision is worth automating. Start with high-volume, time-sensitive decisions where manual rules can’t keep up and where you have outcome data to measure lift.
How does next best action work across channels?
A customer qualifies for a loyalty offer, a cart reminder, and a back-in-stock alert. Which one do you send? On which channel? Or do you send nothing?
The Next Best Action loop resolves this:
- Candidate generation: Pull all actions the customer is eligible for based on segment membership, inventory, and consent
- Scoring: For each candidate, calculate expected value: P(response) × value × uplift × channel affinity
- Constraint filtering: Apply frequency caps, budget limits, and precedence rules
- Selection: Choose the top action. If expected value is below threshold, select “do nothing”
| Action type | Precedence | Rationale |
| Transactional (order confirmation) | Highest | Required; no exclusion |
| Service (support follow-up) | High | Customer-initiated; high urgency |
| Retention (churn intervention) | Medium | High value; time-sensitive |
| Marketing (promotional) | Lowest | Lowest priority; subject to fatigue caps |
If you don’t exclude low-value actions, you’re prioritizing volume over decision quality.
How do send-time and channel optimization work?
Your model says the best time to reach this customer is a specific time on SMS. But they’ve already received several messages today, and your contact policy caps SMS at a strict daily limit.
This is a constrained optimization problem. The engine scores each (channel, time) pair, then filters out options that violate constraints. If no valid option remains, it queues the action for the next available window or excludes it entirely.
Aggressive optimization can create “winner-take-all” dynamics where one channel dominates. Monitor channel distribution and consider exploration budgets to test underused channels.
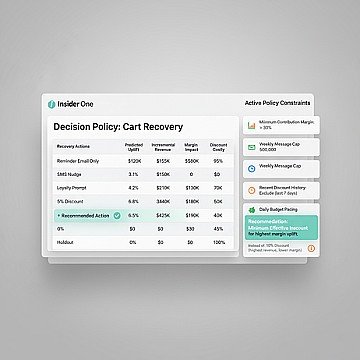
How does cart abandonment recovery benefit from decisioning?
Your abandonment flow recovers carts. With an average 70% abandonment rate across ecommerce, the volume is massive. But how many of those customers would have come back anyway? If you’re not measuring uplift, you’re overstating ROI and potentially training customers to wait for discounts.
Before sending any incentive, check if the customer’s predicted conversion probability without intervention exceeds a threshold. If yes, send a reminder without discount. Reserve discounts for customers with low baseline probability.
Teams often measure recovery rate (conversions attributed to the flow) instead of incremental lift (conversions that wouldn’t have happened otherwise). The former inflates results; the latter tells you what’s actually working. If you want to see what this looks like in a real stack, book a demo and we’ll walk through decisioning, suppression, and uplift measurement end to end.
How does conversational support routing work?
A customer sends a message. Should it go to a bot, a human agent, or a specialized team? Wrong routing creates friction and drives up handle time.
| Intent | Confidence threshold | Routing |
| Order status | High | Bot |
| Password reset | High | Bot |
| Billing dispute | Any | Human (specialized) |
| Product question | High | Bot with escalation |
| Complaint | Any | Human (priority queue) |
Proper routing reduces mishandled tickets, which reduces repeat contacts and improves CSAT. This is how decision engines reduce service errors. Explore working decision flows and channel outcomes in the product demo hub.
Why do AI decision engines benefit marketing teams?
Before decisioning, campaign teams spent hours configuring segment-specific rules. After decisioning, they define objectives and constraints; the engine handles selection and the team focuses on strategy.
- Reduced manual configuration: Instead of building separate journeys for each segment-channel combination, define eligibility rules once and let the engine optimize selection
- Consistent policy enforcement: Frequency caps, consent rules, and brand guidelines apply automatically across all actions, reducing compliance risk
- Measurable incrementality: With proper holdout design, you can isolate the lift from decisioning vs baseline, justifying continued investment
- Faster experimentation: Champion/challenger testing happens automatically; winning variants scale without manual intervention
| Approach | Configuration effort | Consistency | Learning |
| Manual rules | High (per segment, per channel) | Variable | None (static) |
| Rules engine | Medium (centralized rules) | High (enforced) | None (static) |
| Decision engine | Low (objectives + constraints) | High (enforced) | Continuous (feedback loop) |
Decision engines don’t replace strategy. They execute strategy faster and more consistently. If you’re ready to move from complex rules to measurable lift, book a demo and evaluate your top use case with real constraints.
What guardrails make AI decisioning trustworthy?
Stakeholders won’t adopt a system they can’t audit. Decision engines need guardrails that enable speed without sacrificing accountability.
What human-in-the-loop controls do you need?
Which decisions require human review? The answer depends on risk, not volume.
- Approval gates: High-value offers or sensitive segments require manual approval before execution
- Exception queues: Decisions that trigger policy violations or low-confidence scores route to a review queue
- Override logging: When humans override the engine’s recommendation, log the reason. This creates training data and audit trails
Teams either over-gate (every decision requires approval, defeating the purpose) or under-gate (no oversight, creating risk). Start with conservative gates and relax as you build confidence.
How should you test before rollout?
A misconfigured decision engine can send the wrong message to a large number of customers before anyone notices.
- Offline evaluation: Test the new policy/model against historical data
- Shadow mode: Deploy the new version alongside production.